PinnedZecca J. LehnTop-Decile Angel Portfolio of Sustainability Startups 🌱For informational purposes only. Not to be construed as financial advice, nor an offer to buy or sell any securities. No forward looking…12 min read·Aug 22, 2021--1--1
PinnedZecca J. LehnVC Impact LandscapeThere’s a gap in the impact arena, limiting early stage startups seeking Venture Capital. This article is to help Founders and Investors…4 min read·Aug 16, 2020--3--3
Zecca J. LehnWhat is SocialTech and SustainableTech?We just passed over 3.5k members and listeners in our posi2ive club recently on Clubhouse (a sidecar to our podcast) on Venture Scale…3 min read·Mar 28, 2021----
Zecca J. LehnVC Impact Focused Databases for Founders and Investors in 2020Finding ways to connect Investors to Entrepreneurs, is a challenge for both parties. If can be even more difficult to find opportunities…5 min read·Dec 30, 2020--27--27
Zecca J. LehnUnlocked: A Great Book a Week in 2020What a whirlwind this year has been for us all. Finding sanity in this experience is unique to each person. Whatever anyone can do to make…5 min read·Dec 18, 2020----
Zecca J. LehnVirtual, Headless, and Distributed (Oh My!)Fearless Web Scraping with Python in DataLab Notebooks·5 min read·Mar 19, 2019--1--1
Zecca J. LehninTowards Data ScienceEnlightened DataLab NotebooksWith Read/Write Bucket, IAM Permissions, and Safe Firewall Configs·8 min read·Mar 9, 2019----
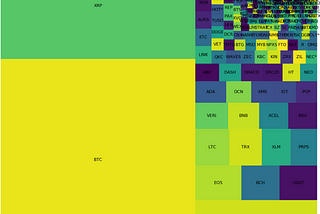
Zecca J. LehninTowards Data ScienceTravelling in the BlockChain Ecosystem with PythonWith over 2500+ active blockchain projects around the globe, each with it’s own unique statistical characteristic, we rarely see a top…6 min read·Jan 31, 2019----
Zecca J. LehnBooting-Up Your Network with GrapheneDB using Neo4j and PythonGraphs (think Vertices and Edges here), where the relationship from metadata provided by social networks, for example, help uncover hidden…6 min read·Dec 17, 2018----